🛠️ 『极客视界』科技达人的综合资讯指南
你是否常常为寻找最新的技术资讯、工具和资源而感到困扰?或者每次开发时都需要开启无数个标签页,才能找到所需的工具和信息?
别担心,让我为你介绍一个好地方『极客视界』,这是每位科技达人的福音、必备的综合资讯指南。
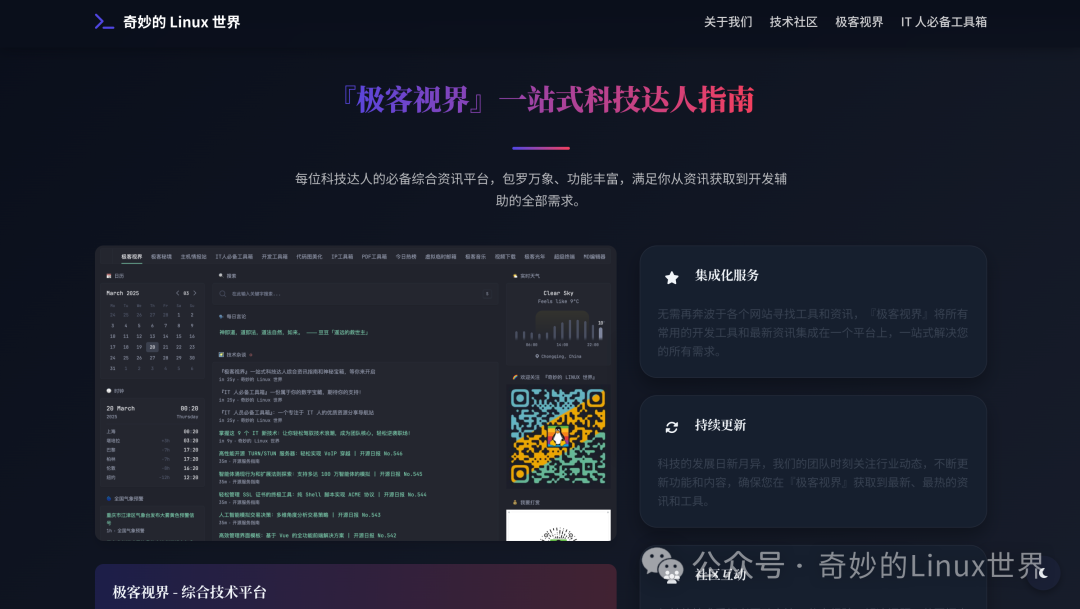
『极客视界』提供了一站式的服务,它包罗万象、功能丰富,直接满足你从资讯获取到开发辅助的全部需求。
从 GitHub 热榜到 PDF 工具箱,从实时新闻资讯、技术文章到虚拟临时邮箱,样样俱全!

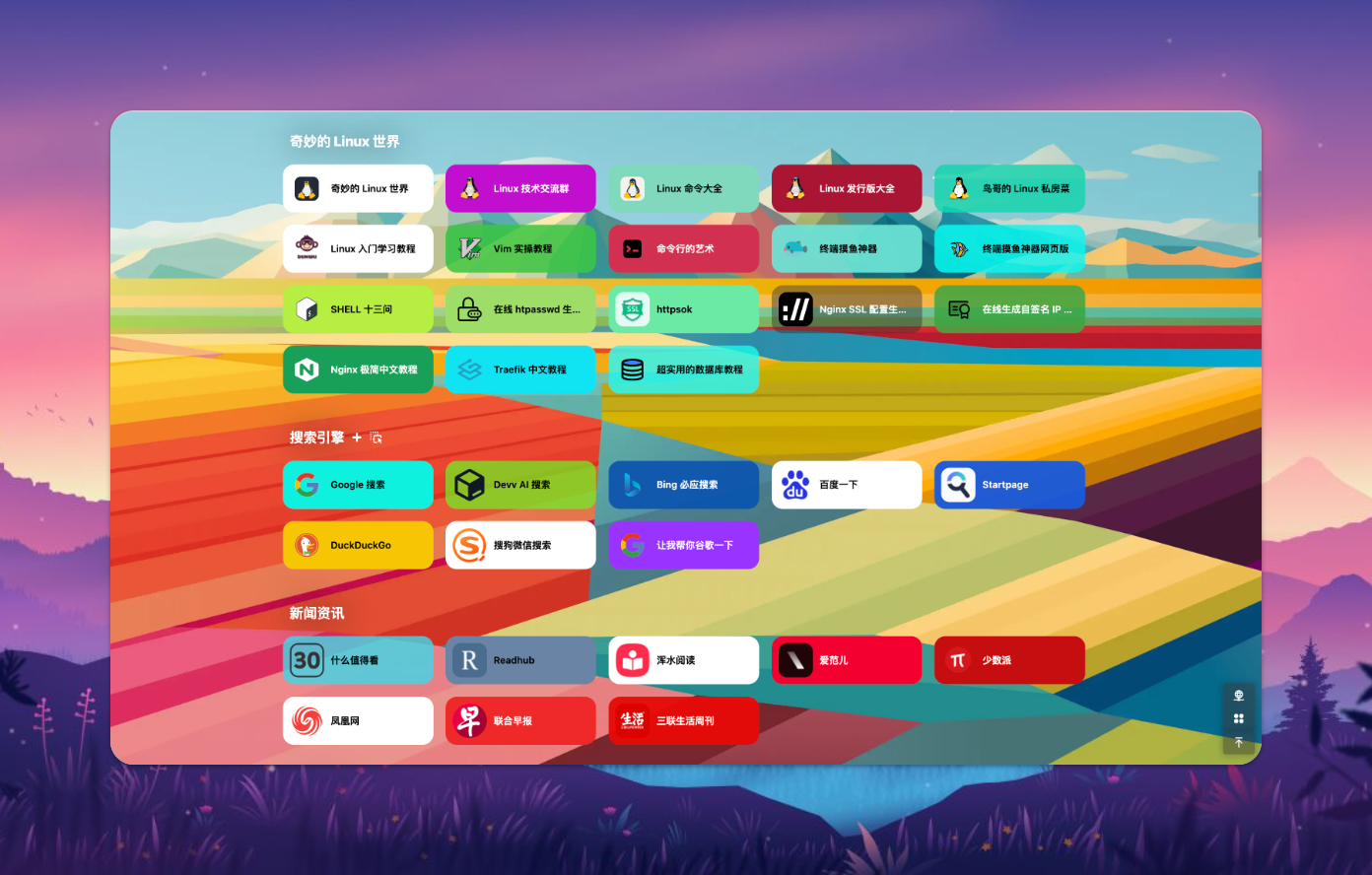
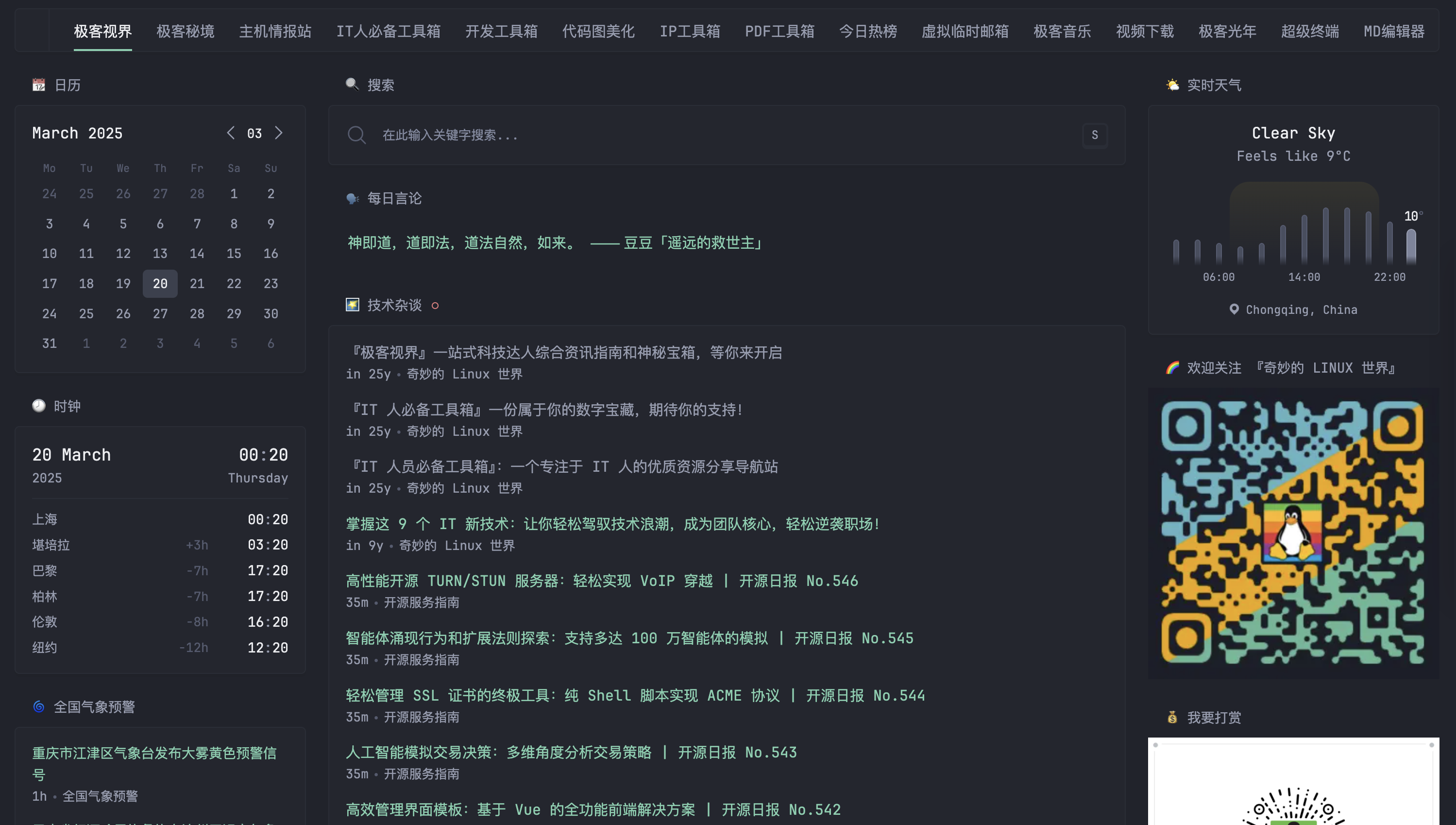
🤓 极客视界
『极客视界』是一个综合科技资讯的枢纽。如果你喜欢紧跟最新的科技动态、追踪热门项目,或是希望时刻了解技术动向,那这个板块绝对不容错过。
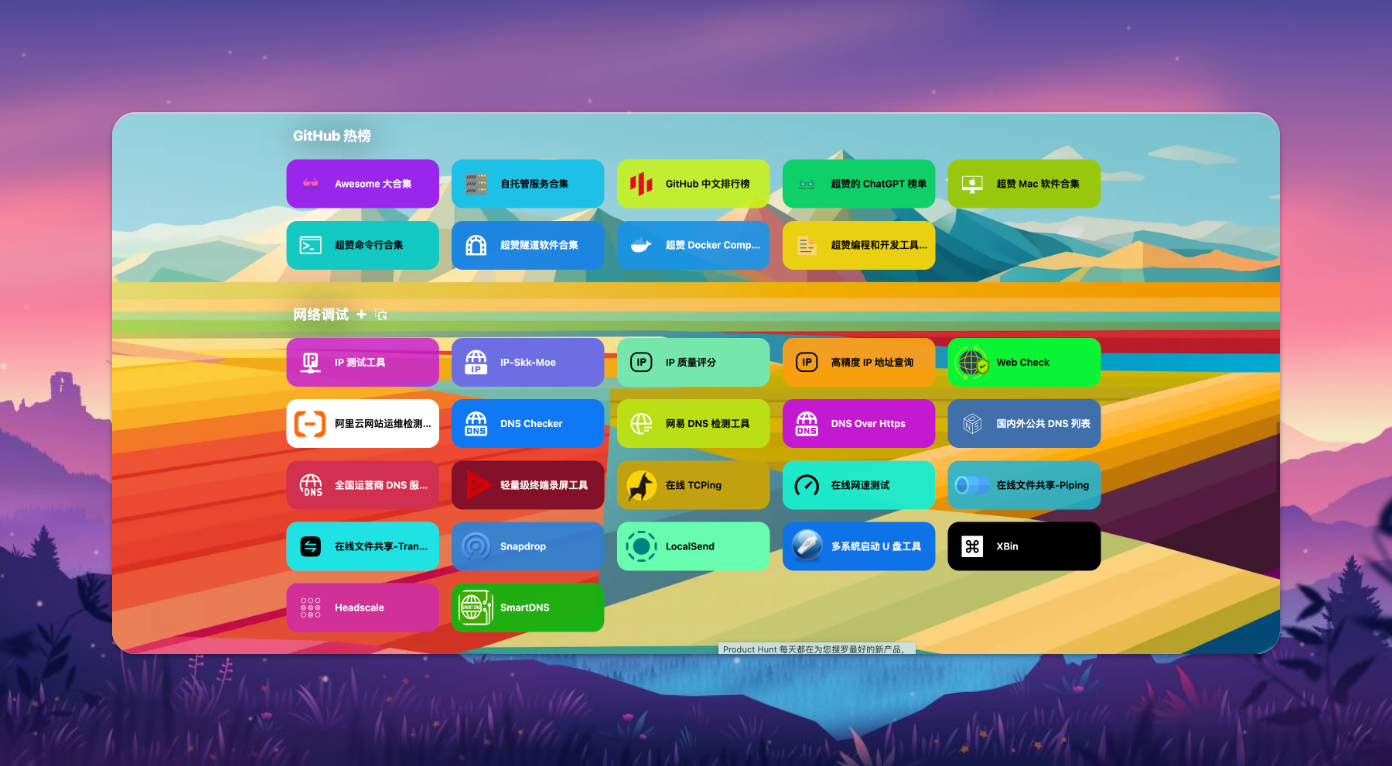
🏆 Github 热榜
每天都有成千上万的项目在 GitHub 上更新,又如何挑选出最热门、最有趣的项目呢?
别担心,『极客视界』已经为你做了筛选。我们提供的每日更新的 GitHub 热门项目榜单,每天看看就知道哪些项目正火热。
实时获取最新最火的开源项目,助你快速了解哪些项目正在迅速蹿红,也可以看看有多少大牛在关注同样的项目,再也不用费力翻找。
📰 最新 IT 新闻和技术文章
获取行业动态和最新资讯是每个极客的日常标配。在『极客视界』,你能找到最新的 IT 新闻和技术文章。
我们涵盖了从前沿技术到开发实战,从行业大事件到新兴趋势的一切内容。
不仅内容丰富,还有专业的编辑团队为你推荐精选文章,让你在最短时间内掌握最有价值的信息。
🧑💻 黑客新闻
这里提供最新、最全的黑客新闻,覆盖广泛的领域。无论是安全漏洞、趋势分析,还是开发者的门道,这里都有。
📈 Github 热门仓库状态跟踪
对你关注的热门仓库进行状态跟踪,实时获取更新信息。再也无须手动查询,每天都能知道自己心仪的仓库发生了哪些变化。
💚 服务监控
对各种网络服务进行监控,只需轻松设置,关键数据一目了然。实时掌握各种关注服务的状态,确保系统平稳运行。
🗞 极客秘境
这里是技术人的宝藏,包括最新的 IT 新闻、技术文章和深度分析,兼具广度和深度。
🤖 AI 新世界
这里聚焦人工智能领域的最新资讯和技术动态,想知道 AI 的新突破、新应用,或者最新的研究成果,这里一站搞定。
📅 科技周刊汇
每周汇总最具价值的科技新闻,如果你是一周一更新的节奏党,这里绝对不会让你错过任何重要信息。
💻 数码潮流
最新数码产品的资讯和评测,从手机到电脑再到各种智能设备。让你在购买之前就对产品有全面的了解,做个不踩雷的科技买手。
🌐 知乎热榜
集成知乎的科技热榜,看看大家都在讨论些什么热门话题。知乎神仙们的回答一定会让你豁然开朗。
🏠 IT 之家热榜
再也不会错过 IT 之家发布的有趣新闻和深度文章,适合 IT 人必读的榜单,全方位提升知识水平。
💡 稀土掘金文章榜
聚集稀土掘金平台的热门技术文章,无论是新工具、新技术,还是各种开发干货,这里都值得一看。
🚀 HelloGithub 热门仓库
专业团队挑选和介绍的 Github 热门仓库,涵盖广泛的编程语言和框架。每期精选,你一定能找到自己感兴趣的项目。
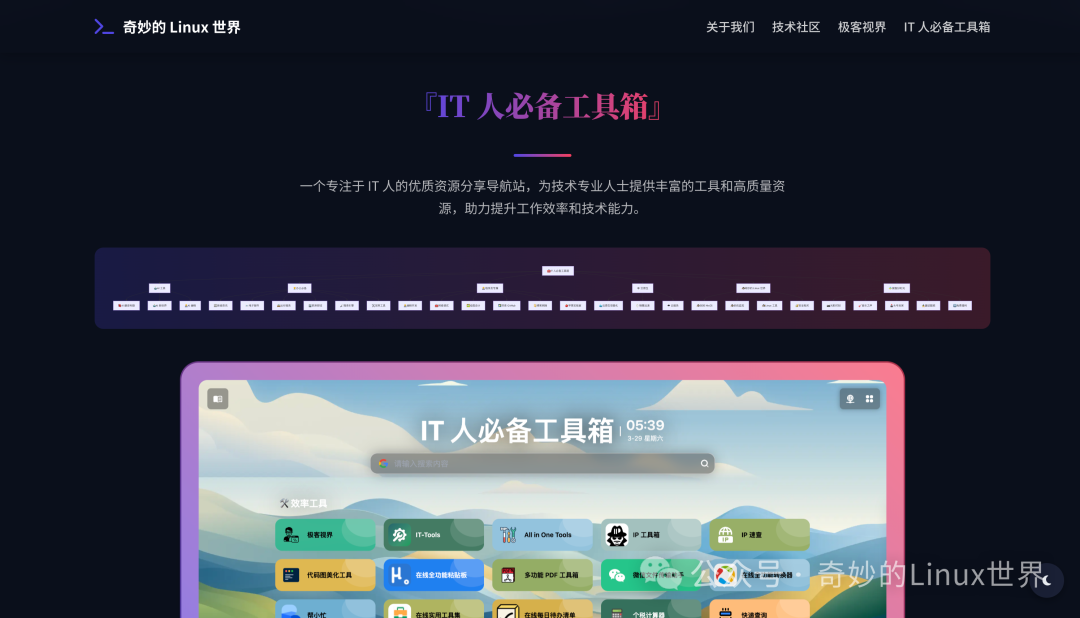
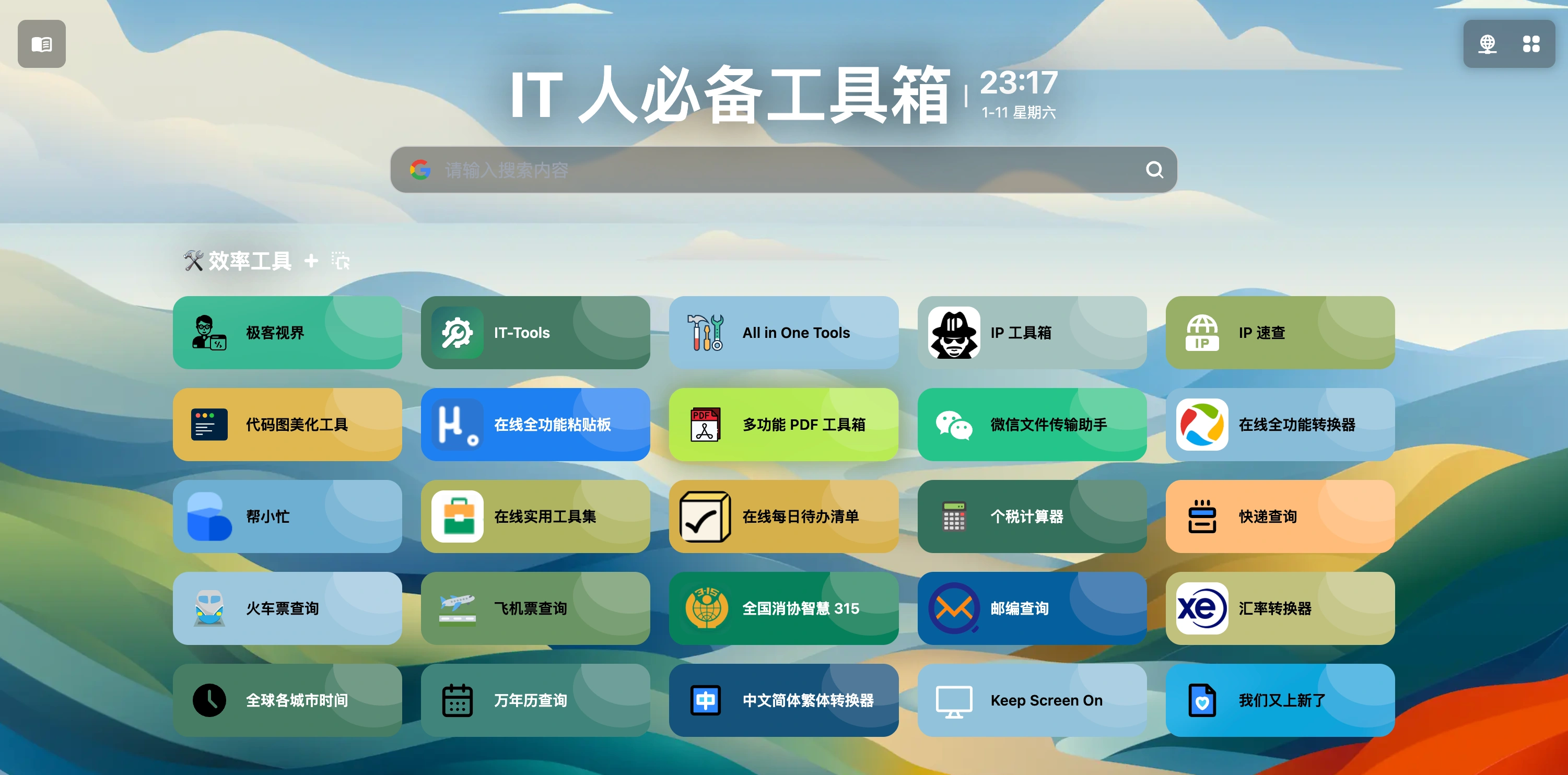
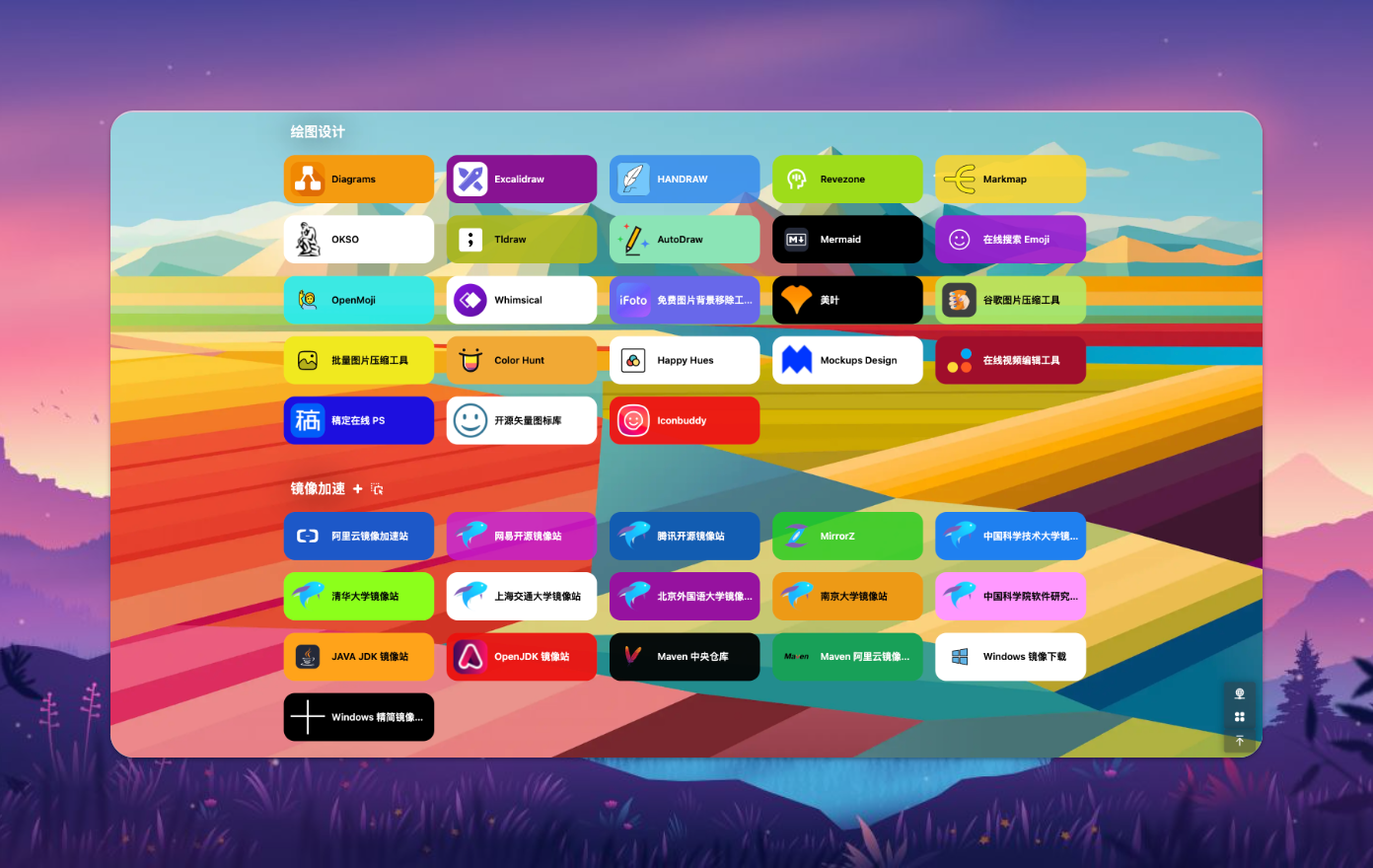
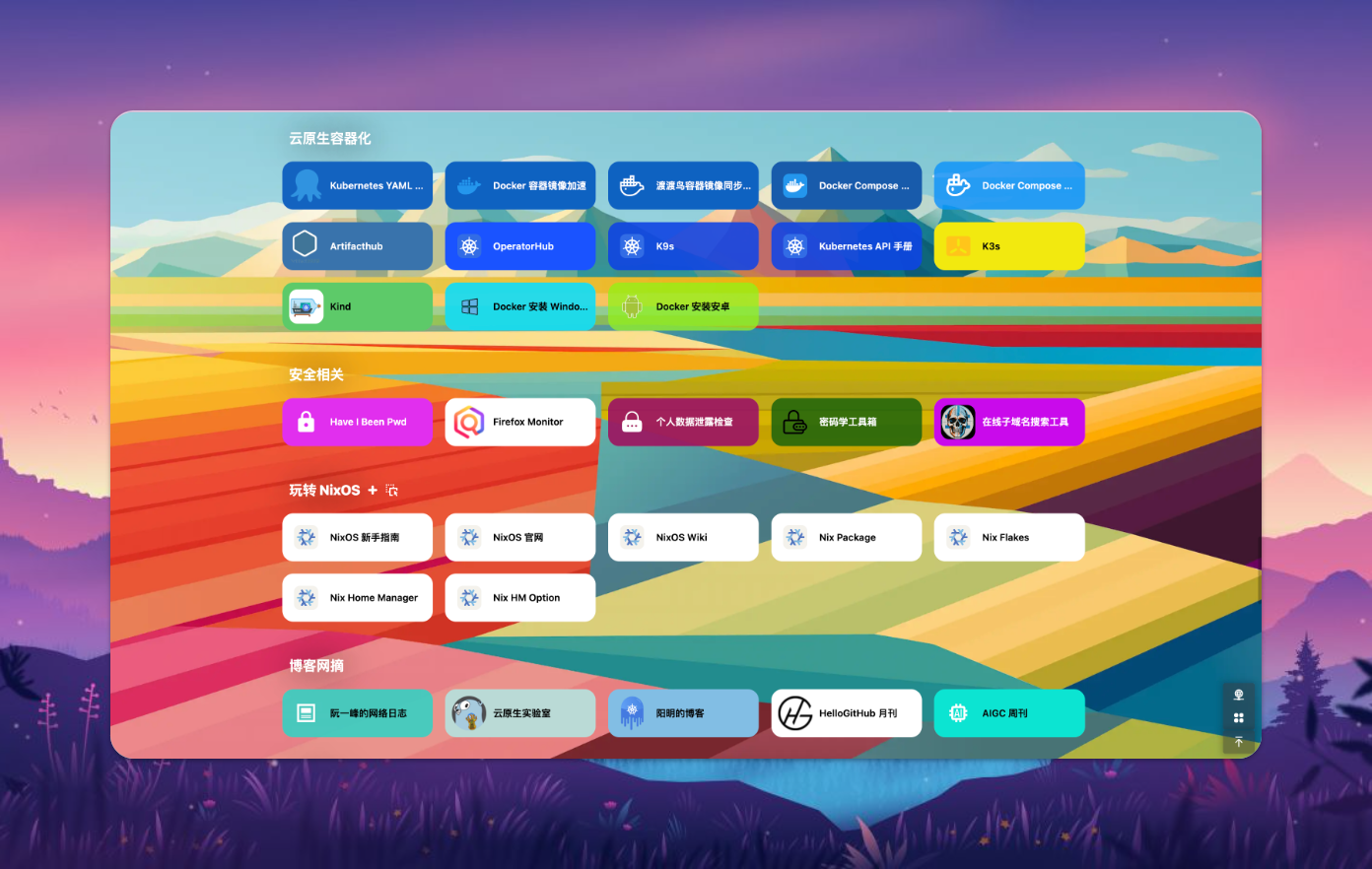
🧰 IT 人必备工具箱
『IT 人必备工具箱』 是每一位 IT 人都不可或缺的资源宝库,里面收纳着各种专注于技术领域的优质资源和实用工具。
它如同一座巨大的数字图书馆,为 IT 从业者提供了丰富的资讯和工具。
让他们在数字世界中驰骋自如,无论是编程开发、网络安全、数据分析还是人工智能。
这个工具箱都汇聚了各种经典和前沿的资源,为 IT 人士解决难题、提升技能提供了强大的支持。
无论是初学者还是资深技术大牛,都可以从中汲取灵感,探索未知,不断成长。
🧑💻 开发工具箱
作为开发者,你一定会喜欢我们的开发工具箱。
这里囊括了各种实用的开发小工具,涵盖了从代码编辑、JSON 解析器、网络调试工具、正则表达式测试器等的一切,应有尽有。
所有的工具都经过精心挑选和测试,确保能在关键时刻帮到你。减少你在开发过程中寻找工具的时间,提升工作效率。
🎨 代码图美化
代码不仅要运行得好,还要看得美。我们的代码图美化工具,可以将你的一段代码精美地呈现出来。
它可以帮助你将代码片段转化成美观的图片,它支持高度定制,照顾到每一个细节,让你的代码更具表现力。
不论是分享给团队成员,还是展示在个人博客上,漂亮的代码图总能让你的工作成果更上一层楼。
🌍 IP 工具箱
无论是开发还是运维,IP 信息总是绕不开的问题。『极客视界』为你准备了全面的 IP 工具箱,涵盖从 IP 查找、IP 段查询到地理位置转换等多种功能,让你轻松搞定所有与 IP 相关的难题。
对于网络管理员和开发者来说,这些功能在日常工作中非常实用。
📄 PDF 工具箱
处理 PDF 文件常常让人头疼,但在『极客视界』这一切都不是问题。我们提供了全方位的 PDF 工具箱,包括 PDF 转换、合并、拆分、压缩等多种功能。
不管你的需求是什么,这里都有合适的工具帮你搞定,一站解决所有需求,让你轻松应对各种文档格式的转换问题。
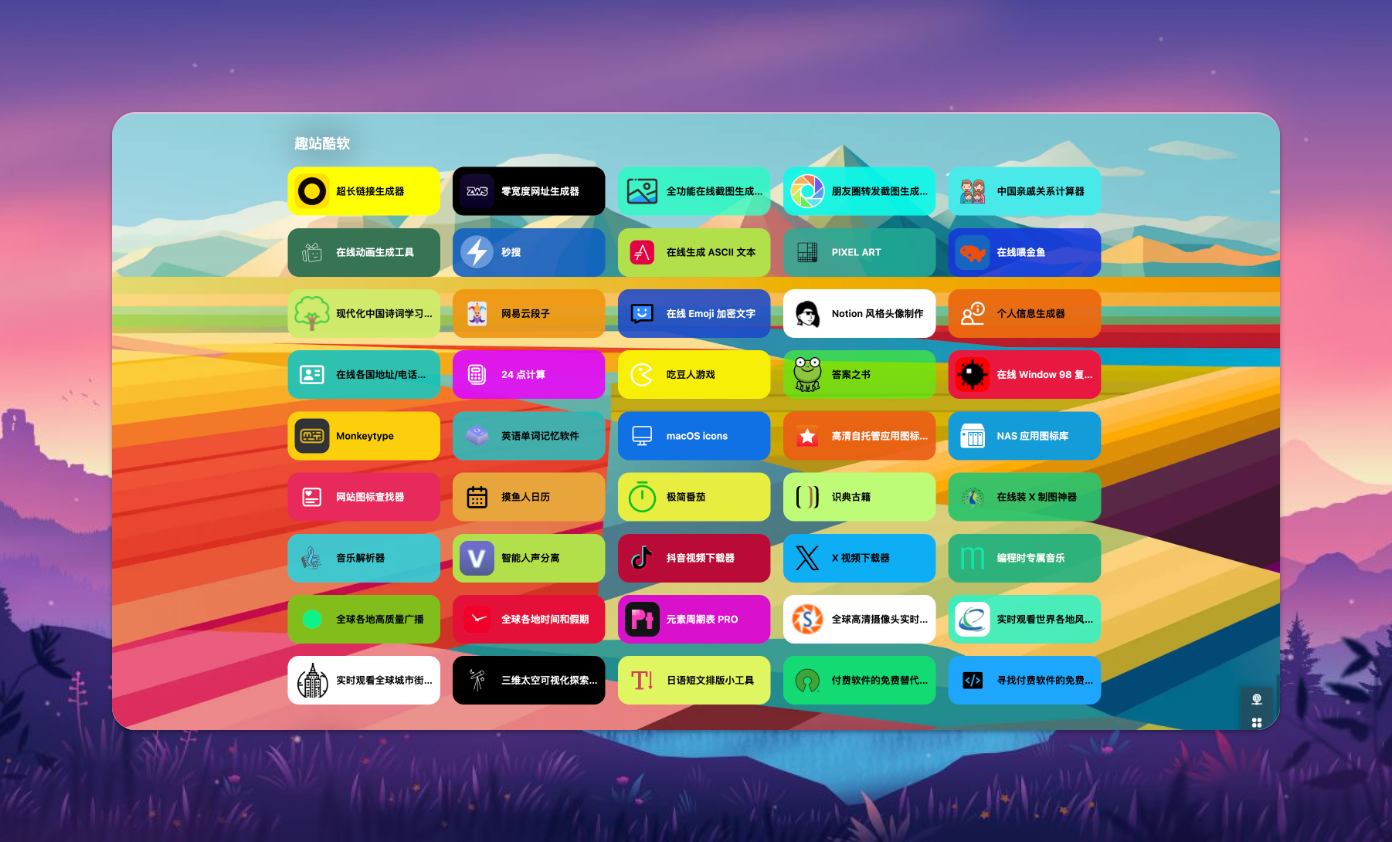
🔥 今日热榜
想知道今天哪些内容最火爆?来看看我们的今日热榜吧!这里汇集了各大平台的热门内容,如微博、知乎、抖音等。
无论是新闻、帖子、视频还是其他内容,最受关注的总能在这里找到。不用再费力刷各大社交媒体,只需一站尽知天下热点,轻松做个潮流达人。
📫 虚拟临时邮箱
注册各种网站服务时,常常会担心邮箱被垃圾信息淹没?
使用我们的虚拟临时邮箱功能吧!它能生成临时邮件地址,帮你保护真实邮箱免受打扰。使用简单方便,一键生成,特别适合短期注册需求。
🖌️ 手绘画板
需要临时记录灵感或进行手绘创作?『极客视界』的手绘画板功能正是为你准备的。
无需下载任何应用,在线即可进行手绘,支持多种笔刷和颜色选择,无论是画草图还是进行简单设计,这里都能得心应手。
📥 视频下载
在线遇到好视频想下载,却苦于找不到合适的工具?
我们提供的在线视频下载工具可以帮你解决这个问题。支持多种视频平台,下载速度快,操作简便,让你轻松保存喜欢的视频内容。
🖥️ 超级终端
如果你经常需要在的终端工作,这个超级终端你一定会爱不释手。它支持各种命令输出,让你看上去很酷而忙碌,是极客必备的利器。
🤔 为什么选择『极客视界』?
🌅 集成化,一站式服务
无需再奔波于各个网站寻找工具和资讯,『极客视界』将所有常用的开发工具和最新资讯集成在一个平台上,一站式解决你的所有需求。
📝 实用性强
我们精心挑选每一项功能和工具,确保它们在实际工作中有用且好用,节省你的时间,提升工作效率。
📈 持续更新
科技的发展日新月异,我们的团队时刻关注行业动态,不断更新功能和内容,确保你在『极客视界』获取到最新、最热的资讯和工具。
🚀 如何开始?
体验所有这些功能只需一个简单的步骤:访问 https://bestgeek.org 开始你的极客之旅吧!
然后根据你的需求选择相应的分类开始探索吧!无论你是开发者、设计师还是普通的科技爱好者,『极客视界』都能为你提供你需要的一切。
🎉 结语
上述功能仅仅是『极客视界』的一部分,我们致力于为每一个热爱科技的朋友提供全面的资讯与工具支持。
『极客视界』不仅是功能齐全的工具和资讯平台,更是每个极客共同的家园。
在这里,你可以找到志同道合的伙伴,获取最新的技术资讯和最实用的开发工具。让我们一起在这个充满科技乐趣的视界里遨游吧!
赶快收藏 极客视界,开启你的科技之旅吧!
]]>