你是不是也跟我一样,每次用 df -h 检查磁盘空间时,盯着那密密麻麻的数字和路径,头都大了?满屏的 “/dev/sda1”、“/mnt/xyz”,看得眼花缭乱,根本分不清哪个盘还有空间,哪个盘已经快爆了!
别急,今天我要给你安利一个超级好用的 Linux 工具 —— dysk!它号称 “比 df 好用 100 倍”,不仅能把文件系统信息整理得清清楚楚,还能让你像玩游戏一样轻松管理磁盘。快来跟我一起看看这玩意儿有多香吧!
啥是 dysk?简单说,它就是磁盘管理的“显微镜”
想象一下,dysk 就像是你电脑里的一位超级整理师。它能把你那些乱七八糟的磁盘信息,比如大小、已用空间、剩余空间、挂载点等等,整理成一张直观的大表格,摆在你面前。比起 df 那冷冰冰的输出,dysk 的界面简直是 “颜值担当”,既好看又好用!
它由一位名叫 Denys Séguret(网名 Canop)的开发者打造,目标就是让 Linux 用户告别 df 的枯燥,轻松掌握文件系统的 “命脉”。而且,dysk 还是免费的开源项目,用起来完全没有心理负担!
Gihtub 项目地址:https://github.com/Canop/dysk
核心功能:让磁盘管理变成 “傻瓜式” 操作
dysk 的核心功能简单粗暴:帮你快速了解和管理文件系统。它不仅能展示信息,还能让你随心所欲调整输出方式,像玩“定制化拼图”一样。下面是它的几个“绝活”,让你用得爽到飞起!
- 表格输出,信息一目了然
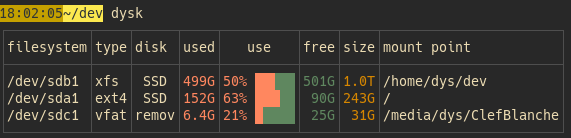
运行 dysk,你会看到一个漂亮的表格,默认显示文件系统(fs)、类型(type)、磁盘(disk)、已用空间(used)、使用率(use)、剩余空间(free)、总大小(size)和挂载点(mp)。
这些信息用颜色区分,清晰又直观,哪怕你是 Linux 小白,也能秒懂哪个盘快满了!想看全部信息?用 dysk -c all,就能显示所有可用列,比如设备 ID(dev)、节点数(inodes)等。不过,官方提醒,-c all 信息量有点大,日常用默认列就够了!
- 灵活筛选,精准锁定目标磁盘
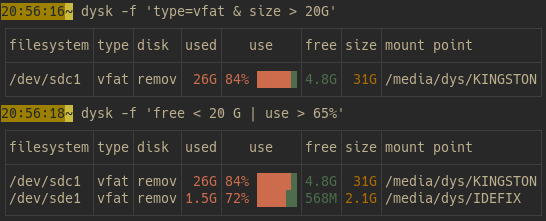
dysk 的筛选功能简直像给磁盘装了个“智能搜索”!用 --filter(或 -f)参数,你可以根据任何列的值筛选文件系统。比如,想看大于 100GB 的磁盘?敲 dysk -f ‘size>100G’,立马挑出大容量盘。想只看 ext4 类型且非远程的磁盘?用 dysk -f 'type=ext4 & remote=false',精准到飞起!支持的运算符有 =、<、>、!=,还能用 |(或)、&(与)、!(非)和括号组合条件,比如 dysk -f '(size<35G | remote=false) & type=xfs',复杂需求也能轻松搞定!默认只显示“常规”文件系统(不含临时或虚拟盘),想看全部?加个 -a 参数就行。
- 排序功能,快速找到 “关键盘”
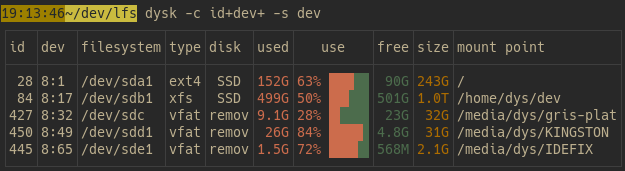
想知道哪个盘最大?哪个最满?dysk 的 --sort(或 -s)参数帮你忙!比如,dysk -s size-desc 按磁盘大小从大到小排序,dysk -s use-desc 按使用率从高到低排,dysk -s type 按文件系统类型排序。支持 asc(升序)或 desc(降序),还能简写成 a 或 d,比如 dysk -s size-a。这功能简直是强迫症患者的福音,数据整齐得像刚收拾好的桌面!
- JSON 和 CSV 输出,程序员的“效率神器”
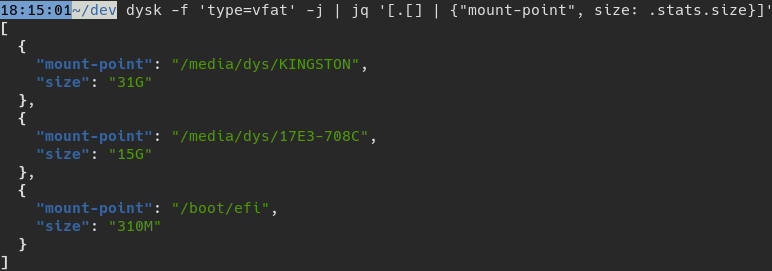
程序员看过来!dysk 支持把数据导出为 JSON 或 CSV,完美适配脚本和报表需求。用 dysk -j(或 --json),输出结构化的 JSON 数组,每个文件系统包含详细信息,比如设备信息(dev)、磁盘类型(disk)、统计数据(stats)等。比如:
1 | [ |
想用 jq 处理?直接 dysk -j | jq '.[] | select(.stats.available < "50G")',找出剩余空间小于 50GB 的磁盘。

CSV 也一样简单,dysk --csv -f 'size>100G' -c remote+default > mounts.csv,还能用 --csv-separator 自定义分隔符,比如 dysk --csv --csv-separator ";"。这些功能让数据分析和自动化脚本轻松上手!
- 自定义列,打造你的专属表格
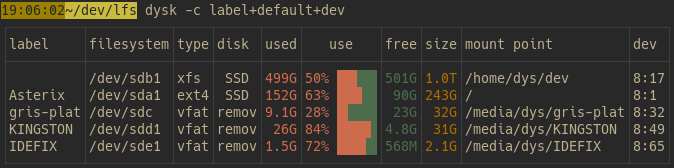
dysk 的表格支持高度自定义,用 --cols(或 -c)参数选择显示的列。比如,dysk -c label+use+size+disk+mount 只显示标签、使用率、大小、磁盘和挂载点。想加节点数?dysk -c +inodes 搞定。想去掉某列?用 -,比如 dysk -c default-use 移除使用率列。还能用 dysk --list-cols 查看所有可用列名,灵活得像搭积木!默认列已经够日常使用,但你随时可以按 spells
- 跨平台支持,连安卓都不放过
dysk 不只支持 Linux,连安卓和 NetBSD 也能跑!它的下载目录提供了各种架构的预编译二进制文件,比如 x86_64、ARM、RISC-V 等等。直接下载,设置权限,丢到 /usr/local/bin,分分钟就能用起来。
安装 dysk:从零到上手,简单到飞起
别担心,dysk 的安装过程跟它的使用一样简单。以下是几种安装方式,适合不同人群,包你分分钟上手!
方式 1:下载预编译二进制文件(最快!)
-
下载文件
打开 dystroy.org/dysk/download,找到适合你系统的版本。比如,Linux 用户可以选 x86_64-linux 下的 dysk_2.10.1.zip(截至 2025 年 5 月 14 日,最新版本是 2.10.1)。安卓用户可以选 aarch64-linux-android,NetBSD 用户也有专门的包!
-
解压并设置权限
下载后解压,比如 unzip dysk_2.10.1.zip,得到一个 dysk 可执行文件。运行 chmod +x dysk 确保它可以执行。然后,移到系统路径,比如 mv dysk /usr/local/bin/,这样就能在任意地方运行 dysk 了。
-
验证安装
敲 dysk --version,如果看到版本号(比如 2.10.1),恭喜你,安装成功!直接运行 dysk,就能看到漂亮的表格输出。
适合人群:不想折腾、追求效率的懒人(像我!)。
方式 2:用 Homebrew 一键安装(Mac 和 Linux 用户专属)
如果你用 Homebrew,直接在终端输入:
1 | $ brew install dysk |
几秒钟后,dysk 就装好了!Homebrew 会自动处理依赖和路径设置,跑 dysk 就能直接用。
适合人群:Homebrew 忠实粉丝,喜欢一键搞定。
方式 3:从源码编译(Rust 爱好者的最爱)
想自己动手编译?dysk 是用 Rust 写的,源码在 GitHub: Canop/dysk。步骤如下:
-
准备 Rust 环境
确保你装了 Rust(可以用 rustup update 更新到最新版)。Ubuntu/Debian 用户可能还需要安装编译依赖,运行:
1
$ sudo apt install build-essential
-
克隆并编译
克隆仓库:
1
2
3$ git clone https://github.com/Canop/dysk
$ cd dysk
$ cargo install --locked --path .编译好的文件在 target/release/dysk。
-
移动到系统路径
运行
mv target/release/dysk /usr/local/bin/,然后敲dysk --version确认安装成功。
适合人群:喜欢折腾源码的技术 geek,或者想体验最新功能的开发者。
安装小贴士
- 遇到问题? 如果编译报错,可能是 Rust 版本太旧(运行 rustup update),或者缺依赖(Ubuntu/Debian 用户试试 sudo apt install build-essential)。
- 安卓用户注意:Termux 用户可以直接用安卓版本的二进制文件,装好后丢到 /data/data/com.termux/files/usr/bin/,一样好使!
- 想确认版本? 随时运行 dysk --version,看看是不是最新版(当前是 2.10.1)。
为什么 dysk 比 df 好用?亲测体验告诉你
我第一次用 dysk 的时候,感觉就像从黑白电视升级到了 4K 大屏!df -h 的输出虽然功能齐全,但信息太密集,经常让我抓瞎。dysk 就不一样了,它把信息整理得像一份精心设计的报表,直观又好看。
比如,我有块磁盘叫 “Obelix”(哈哈,是不是很有个性?),用 df 看的时候,我得费劲找它的挂载点和剩余空间。
用 dysk 呢?直接 dysk -c label+use+free,Obelix 的状态一目了然,剩余 67GB 空间直接跳到我眼前,省时省力!
还有一次,我想找所有大于 500GB 的本地磁盘,用 dysk -f 'size>500G & remote=false',几秒钟就筛选出来,效率高到飞起!相比之下,df 得配合 awk 或 grep 才能干这活,麻烦得要命。
谁适合用 dysk?几乎所有人!
- Linux 新手:dysk 的默认输出简单直观,不用懂太多命令行知识就能上手。
- 运维工程师:筛选和排序功能让你快速定位问题磁盘,省下宝贵时间。
- 程序员:JSON 和 CSV 输出简直是为脚本量身定制,批量处理磁盘信息so easy。
- 强迫症患者:自定义列和排序功能,满足你对数据整洁的极致追求!
不管你是学生、开发者还是服务器管理员,dysk 都能让你的磁盘管理变得轻松又愉快。
实际场景:dysk 怎么帮你省心?
dysk 的强大功能在实际场景中简直是 “救命神器”。以下是几个真实案例,告诉你它怎么让磁盘管理变得轻松又高效!
场景 1:清理磁盘空间
某天你发现 “Obelix” 盘只剩 67GB 空间,急需清理!运行 dysk -s use-desc,立刻看到使用率最高的盘是它,占用 67%(162GB/243GB)。
想知道具体哪些文件占空间?结合 broot 的 “whale spotting” 模式(br -w),按大小排序文件和目录,找到几个大文件,比如 /home/user/Videos/4K_movie.mp4 占了 20GB。
用 dysk -c label+size+mount 确认挂载点,再用 broot 的 Ctrl+G 标记大文件,Ctrl+→ 切换到 staging 面板,输入 :rm 删除,20 GB 空间瞬间解放!整个过程直观又快速,省得你满头大汗翻文件夹。
场景 2:服务器巡检
如果你是运维,管理几十台服务器的磁盘,dysk 是你的 “效率加速器”。运行 dysk -j | jq '.[] | select(.stats.available < "10G")',快速找出剩余空间小于 10GB 的磁盘,比如某个 /dev/sdb1 只剩 8GB。想确认是不是 SSD 盘?用 dysk -f 'disk.type=SSD' -c disk+free,只显示 SSD 磁盘的剩余空间。再用 dysk -s free-asc -f 'remote=false',按剩余空间升序排列本地磁盘,快速定位问题盘,自动化脚本轻松搞定巡检!
场景 3:给老板做报表
老板突然要一份磁盘使用情况的报表?别慌!运行 dysk --csv -f 'size>100G' -c label+use+size+mount > report.csv,生成只包含大于 100GB 磁盘的 CSV 文件,字段包括标签、使用率、大小和挂载点。想用分号分隔?加个 --csv-separator ";"。导入 Excel 稍作美化,报表瞬间高端大气,老板看了直点头!还能用 dysk -c +inodes -f 'inodes.used-percent>80%' 检查节点使用率超 80% 的磁盘,防患于未然。
小彩蛋:dysk 背后的开发者故事
dysk 的作者 Denys Séguret 是个超级有爱的开发者,网名叫 Canop,活跃在 Rust 社区。除了 dysk,他还开发了其他实用工具,比如文件管理神器 broot 和 Rust 代码检查工具 bacon。这些工具都秉承一个理念:简单、直观、好用。他在 dystroy.org 上分享了自己的开发心得,还提供咨询服务,妥妥的技术大牛!
而且,dysk 是完全免费的开源项目,代码托管在 GitHub 上(Canop/dysk)。有 bug 或者新想法?直接去 GitHub 提 issue,或者加入 Miaou 聊天室跟作者聊聊。
总结:dysk,磁盘管理的 “快乐源泉”
用过 dysk 之后,我再也不想碰 df 了!它的直观表格、灵活筛选、强大排序和多样化输出,简直让磁盘管理变成了一种享受。不管你是想快速检查磁盘状态,还是需要深度分析文件系统,dysk 都能让你事半功倍。
快去 dystroy.org/dysk 下载试试吧!装上之后,跑个 dysk,感受一下磁盘管理的 “新世界”。用完记得回来告诉我,你是不是也爱上了这个小神器?评论区见!