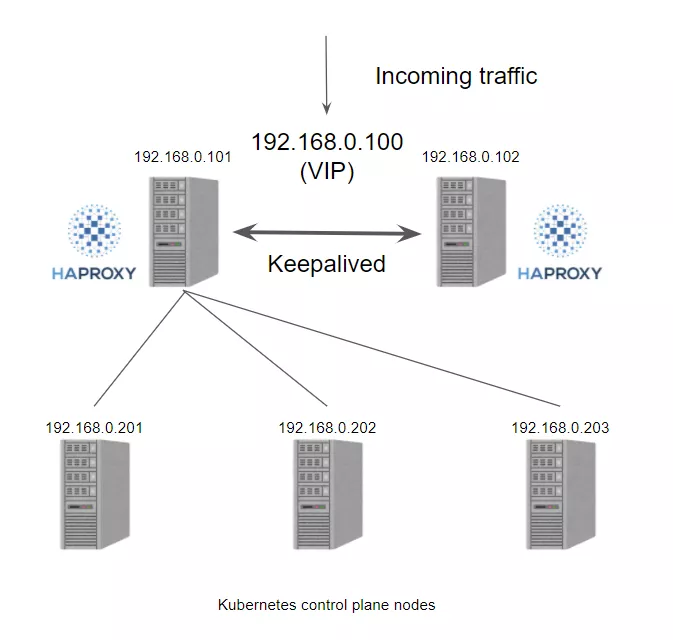
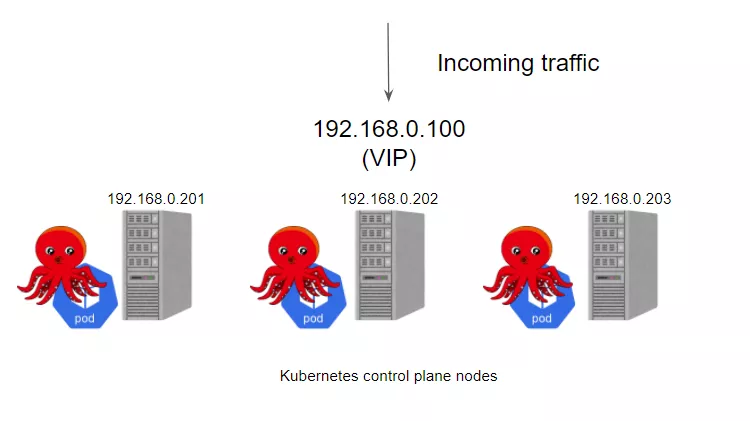
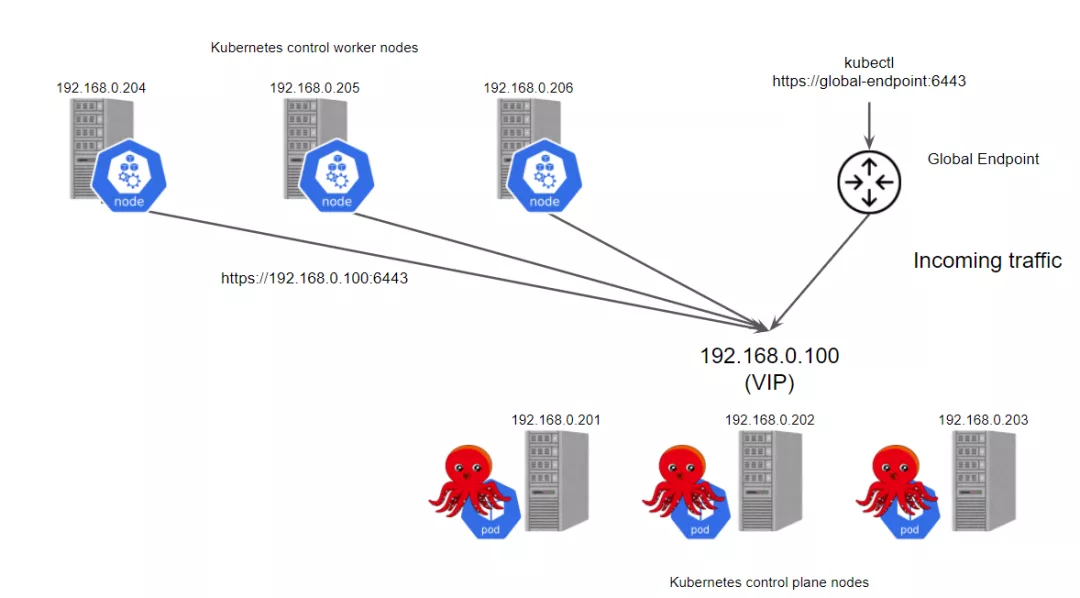
kube-vip 可以通过静态 pod 运行在控制平面节点上,这些 pod 通过ARP 对话来识别每个节点上的其他主机,所以需要在 hosts 文件中设置每个节点的 IP 地址,我们可以选择 BGP 或 ARP 来设置负载平衡器,这与 Metal LB 比较类似。这里我们没有 BGP 服务,只是想快速测试一下,所以这里我们使用 ARP 与静态 pod 的方式。
kube-vip 架构
kube-vip 有许多功能设计选择提供高可用性或网络功能,作为VIP/负载平衡解决方案的一部分。
Cluster
kube-vip 建立了一个多节点或多模块的集群来提供高可用性。在 ARP 模式下,会选出一个领导者,这个节点将继承虚拟 IP 并成为集群内负载均衡的领导者,而在 BGP 模式下,所有节点都会通知 VIP 地址。
当 vip 从一个主机移动到另一个主机时,任何使用 vip 的主机将保留以前的 vip <-> MAC 地址映射,直到 ARP 过期(通常是30秒)并检索到一个新的 vip <-> MAC 映射,这可以通过使用无偿的 ARP 广播来优化。
ARP
kube-vip可以被配置为广播一个无偿的 arp(可选),通常会立即通知所有本地主机 vip <-> MAC 地址映射已经改变。
下面我们可以看到,当 ARP 广播被接收时,故障转移通常在几秒钟内完成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
64 bytes from 192.168.0.75: icmp_seq=146 ttl=64 time=0.258 ms 64 bytes from 192.168.0.75: icmp_seq=147 ttl=64 time=0.240 ms 92 bytes from 192.168.0.70: Redirect Host(New addr: 192.168.0.75) Vr HL TOS Len ID Flg off TTL Pro cks Src Dst 4 5 00 0054 bc98 0 0000 3f 01 3d16 192.168.0.95 192.168.0.75
Request timeout for icmp_seq 148 92 bytes from 192.168.0.70: Redirect Host(New addr: 192.168.0.75) Vr HL TOS Len ID Flg off TTL Pro cks Src Dst 4 5 00 0054 75ff 0 0000 3f 01 83af 192.168.0.95 192.168.0.75
Request timeout for icmp_seq 149 92 bytes from 192.168.0.70: Redirect Host(New addr: 192.168.0.75) Vr HL TOS Len ID Flg off TTL Pro cks Src Dst 4 5 00 0054 2890 0 0000 3f 01 d11e 192.168.0.95 192.168.0.75
Request timeout for icmp_seq 150 64 bytes from 192.168.0.75: icmp_seq=151 ttl=64 time=0.245 ms