警报是监控系统中必不可少的一块, 当然了, 也是最难搞的一块. 我们乍一想, 警报似乎很简单一件事:
假如发生了异常情况, 发送或邮件/消息通知给某人或某频道
一把梭搞起来之后, 就不免有一些小麻烦:
-
这个啊…一天中总有那么几次波动, 也难修难查了, 算了算了不看了
-
警报太多了, 实在看不过来, 屏蔽/归档/放生吧…
-
有毒吧, 这个阈值也太低了
-
卧槽, 这些警报啥意思啊, 发给我干嘛啊?
-
卧槽卧槽卧槽, 怎么一下子几十百来条警报, 哦…原来网络出问题了全崩了
到最后我们还能总结出一个奇怪的规律:
这世界上只有两种警报,一种是疯狂报警但是没有卵用完全没人看的警报,一种是非常有效大家都想看但在用户反馈前从来都报不出来的警报。—— 鲁迅(
玩笑归玩笑,但至少我们能看出,警报不是一个简单的计算+通知系统。只是,”做好警报”这件事本身是个综合问题,代码能解决的也只是其中的一小部分,更多的事情要在组织、人事和管理上去做。我掰不出那么有深度的文章,这篇文章就专注一点,只讲代码部分里的通知,也就是 Prometheus 生态中的 Alertmanager 这个组件。
为什么要 Alertmanager?
我们先介绍一点背景知识,Prometheus 生态中的警报是在 Prometheus Server 中计算警报规则(Alert Rule)并产生的,而所谓计算警报规则,其实就是周期性地执行一段 PromQL,得到的查询结果就是警报,比如:
1 | node_load5 > 20 |
这个 PromQL 会查出所有”在最近一次采样中,5分钟平均 Load 大于 20”的时间序列。这些序列带上它们的标签就被转化为警报。
只是,当 Prometheus Server 计算出一些警报后,它自己并没有能力将这些警报通知出去,只能将警报推给 Alertmanager,由 Alertmanager 进行发送。
这个切分,一方面是出于单一职责的考虑,让 Prometheus “do one thing and do it well”, 另一方面则是因为警报发送确实不是一件”简单”的事,需要一个专门的系统来做好它。可以这么说,Alertmanager 的目标不是简单地”发出警报”,而是”发出高质量的警报”。它提供的高级功能包括但不限于:
-
Go Template 渲染警报内容;
-
管理警报的重复提醒时机与消除后消除通知的发送;
-
根据标签定义警报路由,实现警报的优先级、接收人划分,并针对不同的优先级和接收人定制不同的发送策略;
-
将同类型警报打包成一条通知发送出去,降低警报通知的频率;
-
支持静默规则: 用户可以定义一条静默规则,在一段时间内停止发送部分特定的警报,比如已经确认是搜索集群问题,在修复搜索集群时,先静默掉搜索集群相关警报;
-
支持”抑制”规则(Inhibition Rule): 用户可以定义一条”抑制”规则,规定在某种警报发生时,不发送另一种警报,比如在”A 机房网络故障”这条警报发生时,不发送所有”A 机房中的警报”;
假如你很忙,那么读到这里就完全 OK 了,反正这类文章最大的作用就是让我们”知道有 X 这回事,大概了解有啥特性,当有需求匹配时,能想到试试看 X 合不合适“,其中 X = Alertmanager。当然,假如你是个好奇宝宝,那么还可以看看下面的解析。
Alertmanager 内部架构
先看官方文档中的架构图:
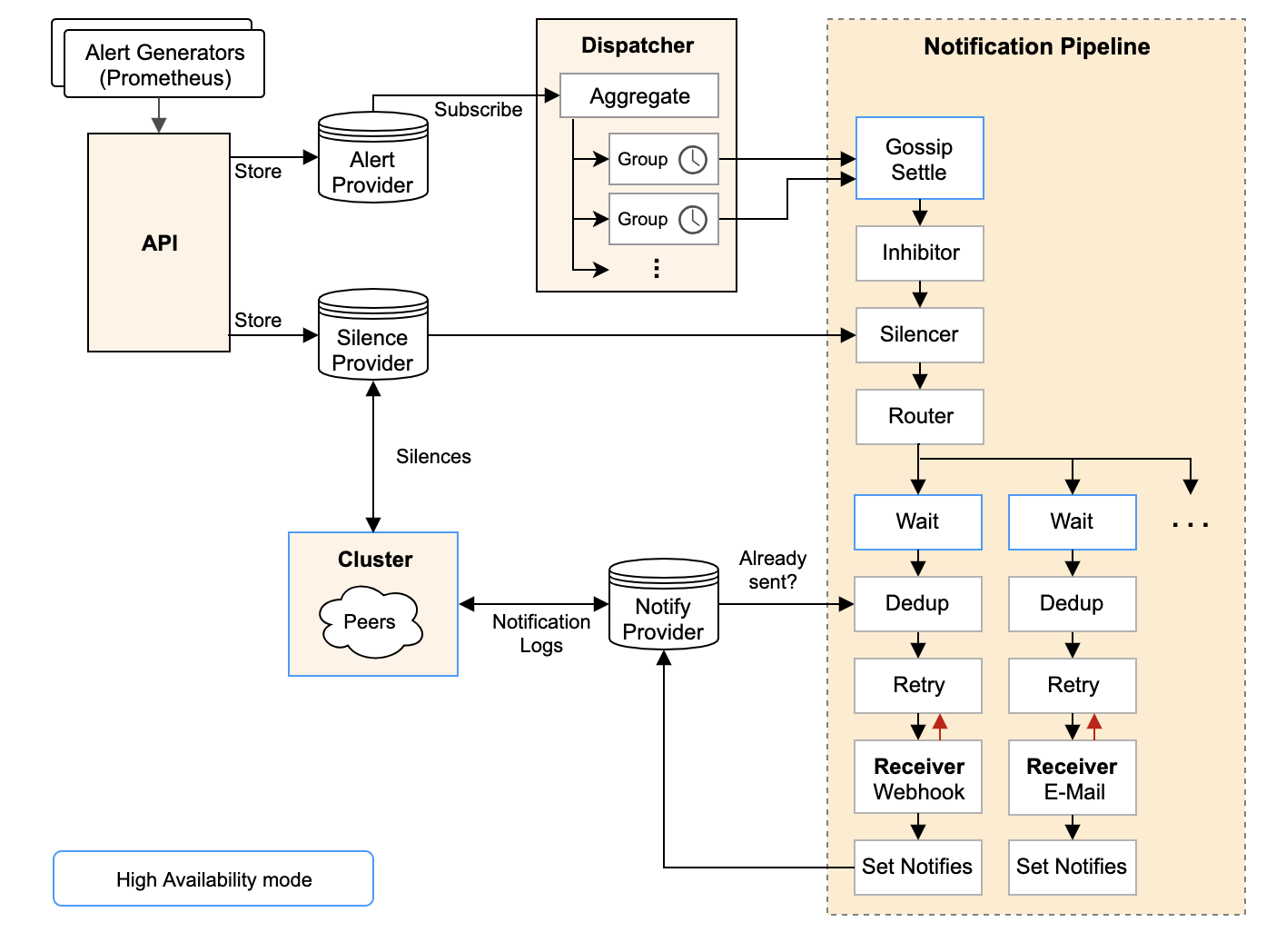
-
从左上开始,Prometheus 发送的警报到 Alertmanager;
-
警报会被存储到 AlertProvider 中,Alertmanager 的内置实现就是包了一个 map,也就是存放在本机内存中,这里可以很容易地扩展其它 Provider;
-
Dispatcher 是一个单独的 goroutine,它会不断到 AlertProvider 拉新的警报,并且根据 YAML 配置的 Routing Tree 将警报路由到一个分组中;
-
分组会定时进行 flush (间隔为配置参数中的 group_interval), flush 后这组警报会走一个 Notification Pipeline 链式处理;
-
Notification Pipeline 为这组警报确定发送目标,并执行抑制逻辑,静默逻辑,去重逻辑,发送与重试逻辑,实现警报的最终投递;
下面就分开讲一讲核心的两块:
-
Dispatcher 中的 Routing Tree 的实现与设计意图
-
Notification Pipeline 的实现与设计意图
Routing Tree
Routing Tree 的是一颗多叉树,节点的数据结构定义如下:
1 | // 节点包含警报的路由逻辑 |
具体的处理代码很简单,深度优先搜索:警报从 root 开始匹配(root 默认匹配所有警报),然后根据节点中定义的 Matchers 检测警报与节点是否匹配,匹配则继续往下搜索,默认情况下第一个”最深”的 match (也就是 DFS 回溯之前的最后一个节点)会被返回。特殊情况就是节点配置了 Continue=true,这时假如这个节点匹配上了,那不会立即返回,而是继续搜索,用于支持警报发送给多方这种场景(比如”抄送”)
1 | # 深度优先搜索 |
为什么要设计一个复杂的 Routing Tree 逻辑呢?我们看看 Prometheus 官方的配置例子: 为了简化编写,Alertmanager 的设计是根节点的所有参数都会被子节点继承(除非子节点重写了这个参数)
1 | route: |
总结一下,Routing Tree 的设计意图是让用户能够非常自由地给警报归类,然后根据归类后的类别来配置要发送给谁以及怎么发送:
-
发送给谁?上面已经做了很好的示例,’数据库警报’和’前端警报’都有特定的接收组,都没有匹配上那么就是’默认警报’, 发送给默认接收组
-
怎么发送?对于一类警报,有个多个字段来配置发送行为:
-
group_by:决定了警报怎么分组,每个 group 只会定时产生一次通知,这就达到了降噪的效果,而不同的警报类别分组方式显然是不一样的,举个例子:
-
配置中的 ‘数据库警报’ 是按 ‘集群’ 和 ‘规则名’ 分组的,这表明对于数据库警报,我们关心的是“哪个集群的哪个规则出问题了”,比如一个时间段内,’华东’集群产生了10条 ‘API响应时间过长’ 警报,这些警报就会聚合在一个通知里发出来;
-
配置中的 ‘前端警报’ 是按 ‘产品’ 和 ‘环境’ 分组的, 这表明对于前端警报,我们关心的是“哪个产品的哪个环境出问题了”
-
-
group_interval 和 group_wait: 控制分组的细节,不细谈,其中 group_interval 控制了这个分组最快多久执行一次 Notification Pipeline
-
repeat_interval: 假如一个相同的警报一直 FIRING,Alertmanager 并不会一直发送警报,而会等待一段时间,这个等待时间就是 repeat_interval,显然,不同类型警报的发送频率也是不一样的
-
group_interval 和 repeat_interval 的区别会在下文中详述
Notification Pipeline
由 Routing Tree 分组后的警报会触发 Notification Pipeline:
-
当一个 AlertGroup 新建后,它会等待一段时间(group_wait 参数),再触发第一次 Notification Pipeline
-
假如这个 AlertGroup 持续存在,那么之后每隔一段时间(group_interval 参数),都会触发一次 Notification Pipeline
每次触发 Notification Pipeline,AlertGroup 都会将组内所有的 Alert 作为一个列表传进 Pipeline, Notification Pipeline 本身是一个按照责任链模式设计的接口,MultiStage 这个实现会链式执行所有的 Stage:
1 | // A Stage processes alerts under the constraints of the given context. |
MultiStage 里塞的就是开头架构图里画的 InhibitStage、SilenceStage…这么一条链式处理的流程,这里要提一下,官方的架构图画错了,RoutingStage 其实处在整个 Pipeline 的首位,不过这个顺序并不影响逻辑。 要重点说的是DedupStage和NotifySetStage它俩协同负责去重工作,具体做法是:
-
NotifySetStage 会为发送成功的警报记录一条发送通知,key 是’接收组名字’+’GroupKey 的 key 值’,value 是当前 Stage 收到的 []Alert (这个列表和最开始进入 Notification Pipeline 的警报列表有可能是不同的,因为其中有些 Alert 可能在前置 Stage 中已经被过滤掉了)
-
DedupStage 中会以’接收组名字’+’GroupKey 的 key 值’为 key 查询通知记录,假如:
-
查询无结果,那么这条通知没发过,为这组警报发送一条通知;
-
查询有结果,那么查询得到已经发送过的一组警报 S,判断当前的这组警报 A 是否为 S 的子集:
-
假如 A 是 S 的子集,那么表明 A 和 S 重复,这时候要根据 repeat_interval 来决定是否再次发送:
-
距离 S 的发送时间已经过去了足够久(repeat_interval),那么我们要再发送一遍;
-
距离 S 的发送时间还没有达到 repeat_interval,那么为了降低警报频率,触发去重逻辑,这次我们就不发了;
-
-
假如 A 不是 S 的子集,那么 A 和 S 不重复,需要再发送一次; 上面的表述可能有些抽象,最后表现出来的结果是:
-
-
-
假如一个 AlertGroup 里的警报一直发生变化,那么虽然每次都是新警报,不会被去重,但是由于 group_interval (假设是5分钟)存在,这个 AlertGroup 最多 5 分钟触发一次 Notification Pipeline,因此最多也只会 5 分钟发送一条通知;
-
假如一个 AlertGroup 里的警报一直不变化,就是那么几条一直 FIRING 着,那么虽然每个 group_interval 都会触发 Notification Pipeline,但是由于 repeate_interval(假设是1小时)存在,因此最多也只会每 1 小时为这个重复的警报发送一条通知; 再说一下 Silence 和 Inhibit,两者都是基于用户主动定义的规则的:
-
Silence Rule:静默规则用来关闭掉部分警报的通知,比如某个性能问题已经修复了,但需要排期上线,那么在上线前就可以把对应的警报静默掉来减少噪音;
-
Inhibit Rule:抑制规则用于在某类警报发生时,抑制掉另一类警报,比如某个机房宕机了,那么会影响所有上层服务,产生级联的警报洪流,反而会掩盖掉根本原因,这时候抑制规则就有用了; 因此 Notification Pipeline 的设计意图就很明确了:通过一系列逻辑(如抑制、静默、去重)来获得更高的警报质量,由于警报质量的维度很多(剔除重复、类似的警报,静默暂时无用的警报,抑制级联警报),因此 Notification Pipeline 设计成了责任链模式,以便于随时添加新的环节来优化警报质量
一个 Prometheus 报警处理实例
最近又被问到了 Prometheus 为啥不报警,恰好回忆起之前经常解答相关问题,不妨写一篇文章来解决下面两个问题:
-
我的 Prometheus 为啥报警?
-
我的 Prometheus 为啥不报警?
从 for 参数开始
我们首先需要一些背景知识:Prometheus 是如何计算并产生警报的?
看一条简单的警报规则:
1 | - alert: KubeAPILatencyHigh |
这条警报的大致含义是,假如 kube-apiserver 的 P99 响应时间大于 4 秒,并持续 10 分钟以上,就产生报警。
首先要注意的是由 for 指定的 Pending Duration。这个参数主要用于降噪,很多类似响应时间这样的指标都是有抖动的,通过指定 Pending Duration,我们可以 过滤掉这些瞬时抖动,让 on-call 人员能够把注意力放在真正有持续影响的问题上。
那么显然,下面这样的状况是不会触发这条警报规则的,因为虽然指标已经达到了警报阈值,但持续时间并不够长:

但偶尔我们也会碰到更奇怪的事情。
为什么不报警?
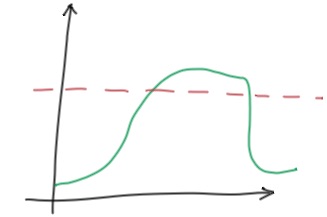
类似上面这样持续超出阈值的场景,为什么有时候会不报警呢?
为什么报警?
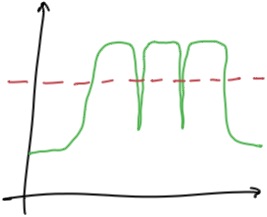
类似上面这样并未持续超出阈值的场景,为什么有时又会报警呢?
采样间隔
这其实都源自于 Prometheus 的数据存储方式与计算方式。
首先,Prometheus 按照配置的抓取间隔(scrape_interval)定时抓取指标数据,因此存储的是形如 (timestamp, value) 这样的采样点。
对于警报, Prometheus 会按固定的时间间隔重复计算每条警报规则,因此警报规则计算得到的只是稀疏的采样点,而警报持续时间是否大于 for 指定的 Pending Duration 则是由这些稀疏的采样点决定的。
而在 Grafana 渲染图表时,Grafana 发送给 Prometheus 的是一个 Range Query,其执行机制是从时间区间的起始点开始,每隔一定的时间点(由 Range Query 的 step 请求参数决定) 进行一次计算采样。
这些结合在一起,就会导致警报规则计算时“看到的内容”和我们在 Grafana 图表上观察到的内容不一致,比如下面这张示意图:
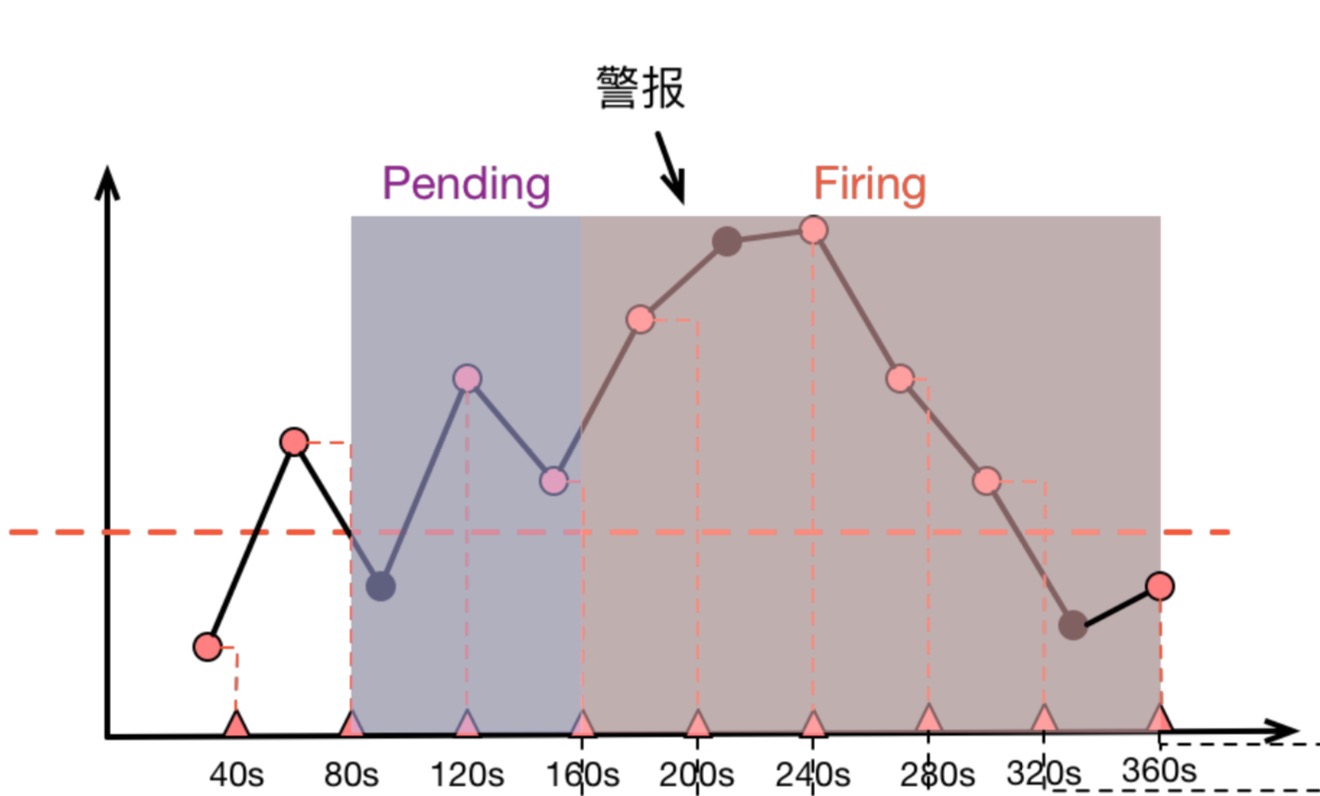
上面图中,圆点代表原始采样点:
-
40s 时,第一次计算,低于阈值
-
80s 时,第二次计算,高于阈值,进入 Pending 状态
-
120s 时,第三次计算,仍然高于阈值,90s 处的原始采样点虽然低于阈值,但是警报规则计算时并没有”看到它“
-
160s 时,第四次计算,高于阈值,Pending 达到 2 分钟,进入 firing 状态
-
持续高于阈值
-
直到 360s 时,计算得到低于阈值,警报消除
由于采样是稀疏的,部分采样点会出现被跳过的状况,而当 Grafana 渲染图表时,取决于 Range Query 中采样点的分布,图表则有可能捕捉到 被警报规则忽略掉的”低谷“(图三)或者也可能无法捕捉到警报规则碰到的”低谷“(图二)。如此这般,我们就被”图表“给蒙骗过去,质疑起警报来了。
如何应对
首先嘛, Prometheus 作为一个指标系统天生就不是精确的——由于指标本身就是稀疏采样的,事实上所有的图表和警报都是”估算”,我们也就不必 太纠结于图表和警报的对应性,能够帮助我们发现问题解决问题就是一个好监控系统。当然,有时候我们也得证明这个警报确实没问题,那可以看一眼 ALERTS 指标。ALERTS 是 Prometheus 在警报计算过程中维护的内建指标,它记录每个警报从 Pending 到 Firing 的整个历史过程,拉出来一看也就清楚了。
但有时候 ALERTS 的说服力可能还不够,因为它本身并没有记录每次计算出来的值到底是啥,而在我们回头去考证警报时,又无法选取出和警报计算过程中一模一样的计算时间点, 因此也就无法还原警报计算时看到的计算值究竟是啥。这时候终极解决方案就是把警报所要计算的指标定义成一条 Recording Rule,计算出一个新指标来记录计算值,然后针对这个 新指标做阈值报警。kube-prometheus 的警报规则中就大量采用了这种技术。
到此为止了吗?
Prometheus 警报不仅包含 Prometheus 本身,还包含用于警报治理的 Alertmanager,我们可以看一看上面那张指标计算示意图的全图:
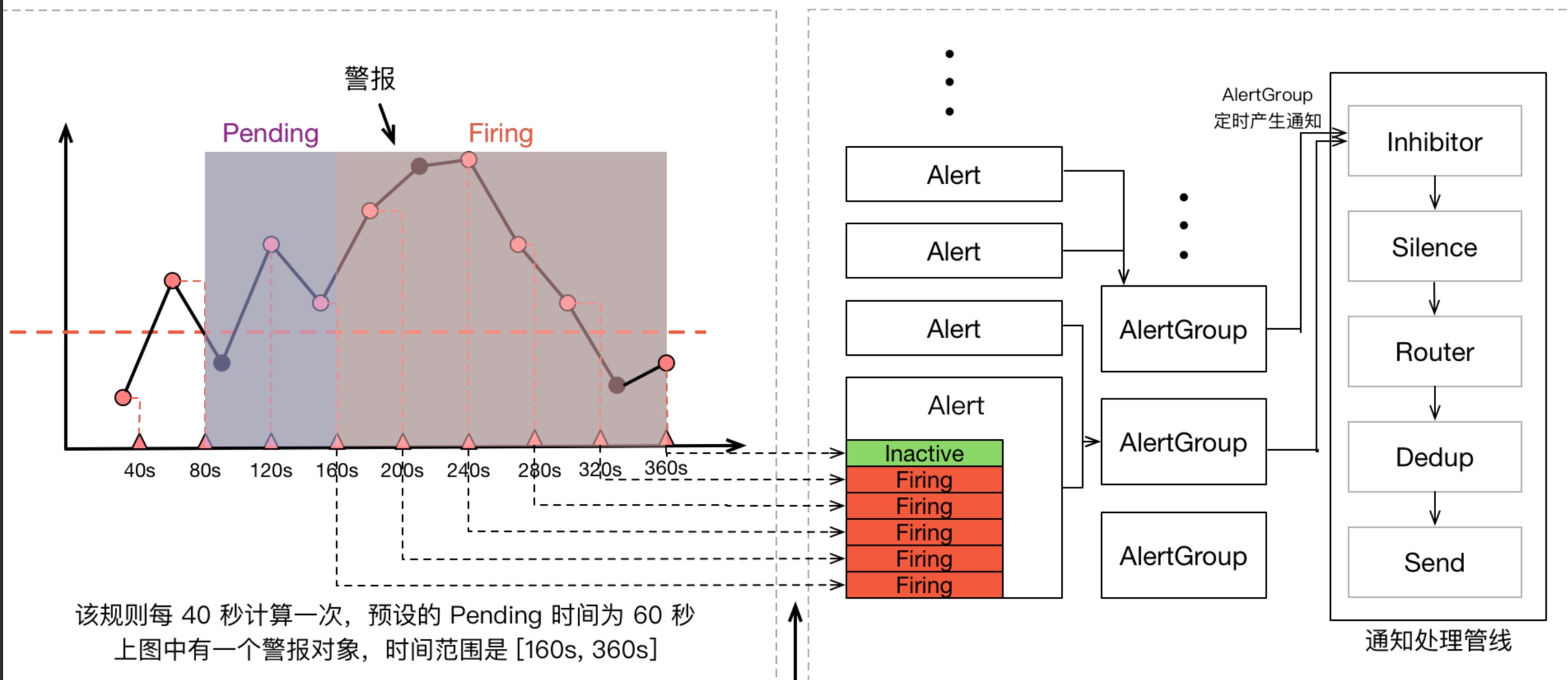
在警报产生后,还要经过 Alertmanager 的分组、抑制处理、静默处理、去重处理和降噪处理最后再发送给接收者。而这个过程也有大量的因素可能会导致警报产生了却最终没有进行通知。
结语
Alertmanager 整体的设计意图就是奔着治理警报(通知)去的,首先它用 Routing Tree 来帮助用户定义警报的归类与发送逻辑,然后再用 Notification Pipeline 来做抑制、静默、去重以提升警报质量。这些功能虽然不能解决”警报”这件事中所有令人头疼的问题,但确实为我们着手去解决”警报质量”相关问题提供了趁手的工具。
本文转载自:「Aylei’s Blog」,原文:1.https://url.cn/5Gp0VLq、2.https://url.cn/5MEMY8K,版权归原作者所有。欢迎投稿,投稿邮箱:
editor@hi-linux.com。