Kubernetes 高可用也许是完成了初步的技术评估,打算将生产环境迁移进 Kubernetes 集群之前普遍面临的问题。 为了减少因为服务器当机引起的业务中断,生产环境中的业务系统往往已经做好了高可用,而当引入 Kubernetes 这一套新的集群管理系统之后,服务器不再是单一的个体,位于中央位置的 Kubernetes Master 一旦中断服务,将导致所有 Node 节点均不可控,有可能造成严重的事故。
总体来讲这是一个被多次讨论,但暂时没有形成统一解决方案的话题。今天主要介绍一些 Kubernetes Master 高可用的策略,供大家参考。
一个小目标
高可用是复杂的系统工程。出于篇幅的考虑以及能力的限制,今天我们先关注一个小目标:所有的 Kubernetes Master 服务器没有单点故障,任何一台服务器当机均不影响 Kubernetes 的正常工作。
实现这一目标带来的直接收益是我们可以在不影响业务正常运行的前提下实现所有服务器的滚动升级,有助于完成系统组件升级以及安全补丁的下发。
为了实现没有单点故障的目标,需要为以下几个组件建立高可用方案:
这些组件的关系可参考下面这张集群架构示意图。
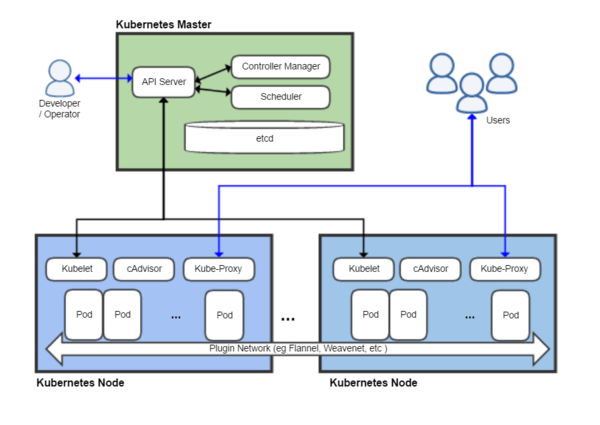
下面为大家逐个详细介绍各个组件的高可用策略。
etcd高可用
etcd 是 Kubernetes 当中唯一带状态的服务,也是高可用的难点。Kubernetes 选用 etcd 作为它的后端数据存储仓库正是看重了其使用分布式架构,没有单点故障的特性。
虽然单节点的 etcd 也可以正常运行。但是推荐的部署方案均是采用 3 个或者 5 个节点组成 etcd 集群,供 Kubernetes 使用。
大家常使用的 kubeadm 工具默认是在一个单节点上启动 etcd 以及所有的 Master 组件。虽然使用起来非常方便,但是要用到生产环境还是要注意这个节点当机的风险。
etcd 的高可用基本有三种思路:
一是使用独立的 etcd 集群,使用 3 台或者 5 台服务器只运行 etcd,独立维护和升级。甚至可以使用 CoreOS 的 update-engine 和 locksmith 让服务器完全自主的完成升级。这个 etcd 集群将作为基石用于构建整个集群。采用这项策略的主要动机是 etcd 集群的节点增减都需要显式的通知集群,保证 etcd 集群节点稳定可以更方便的用程序完成集群滚动升级,减轻维护负担。
二是在 Kubernetes Master 上用 static pod 的形式来运行 etcd,并将多台 Kubernetes Master 上的 etcd 组成集群。 在这一模式下,各个服务器的 etcd 实例被注册进了 Kubernetes 当中,虽然无法直接使用 kubectl 来管理这部分实例,但是监控以及日志搜集组件均可正常工作。在这一模式运行下的 etcd 可管理性更强。
三是使用 CoreOS 提出的 self-hosted etcd 方案,将本应在底层为 Kubernetes 提供服务的 etcd 运行在 Kubernetes 之上。 实现 Kubernetes 对自身依赖组件的管理。在这一模式下的 etcd 集群可以直接使用 etcd-operator 来自动化运维,最符合 Kubernetes 的使用习惯。
这三种思路均可以实现 etcd 高可用的目标,但是在选择过程中却要根据实际情况做出一些判断。简单来讲预算充足但保守的项目选方案一, 想一步到位并愿意承担一定风险的项目选方案三。折中一点选方案二。各个方案的优劣以及做选择过程中的取舍在这里就不详细展开了,对这块有疑问的朋友可以私下联系交流。
kube-apiserver 高可用
apiserver 本身是一个无状态服务,要实现其高可用相对要容易一些,难点在于如何将运行在多台服务器上的 apiserver 用一个统一的外部入口暴露给所有 Node 节点。
说是难点,其实对于这种无状态服务的高可用,我们在设计业务系统的高可用方案时已经有了相当多的经验积累。需要注意的是 apiserver 所使用的 SSL 证书要包含外部入口的地址,不然 Node 节点无法正常访问 apiserver。
apiserver 的高可用也有三种基本思路:
一是使用外部负载均衡器,不管是使用公有云提供的负载均衡器服务或是在私有云中使用 LVS 或者 HaProxy 自建负载均衡器都可以归到这一类。 负载均衡器是非常成熟的方案,在这里略过不做过多介绍。如何保证负载均衡器的高可用,则是选择这一方案需要考虑的新问题。
二是在网络层做负载均衡。比如在 Master 节点上用 BGP 做 ECMP,或者在 Node 节点上用 iptables 做 NAT 都可以实现。采用这一方案不需要额外的外部服务,但是对网络配置有一定的要求。
三是在 Node 节点上使用反向代理对多个 Master 做负载均衡。这一方案同样不需要依赖外部的组件,但是当 Master 节点有增减时,如何动态配置 Node 节点上的负载均衡器成为了另外一个需要解决的问题。
从目前各个集群管理工具的选择来看,这三种模式都有被使用,目前还没有明确的推荐方案产生。建议在公有云上的集群多考虑第一种模式,在私有云环境中由于维护额外的负载均衡器也是一项负担,建议考虑第二种或是第三种方案。
kube-controller-manager 与 kube-scheduler 高可用
这两项服务是 Master 节点的一部分,他们的高可用相对容易,仅需要运行多份实例即可。这些实例会通过向 apiserver 中的 Endpoint 加锁的方式来进行 leader election, 当目前拿到 leader 的实例无法正常工作时,别的实例会拿到锁,变为新的 leader。
目前在多个 Master 节点上采用 static pod 模式部署这两项服务的方案比较常见,激进一点也可以采用 self-hosted 的模式,在 Kubernetes 之上用 DaemonSet 或者 Deployment 来部署。
Kube-dns 高可用
严格来说 kube-dns 并不算是 Master 组件的一部分,因为它是可以跑在 Node 节点上,并用 Service 向集群内部提供服务的。但在实际环境中,由于默认配置只运行了一份 kube-dns 实例,在其升级或是所在节点当机时,会出现集群内部 dns 服务不可用的情况,严重时会影响到线上服务的正常运行。
为了避免故障,请将 kube-dns 的 replicas 值设为 2 或者更多,并用 anti-affinity 将他们部署在不同的 Node 节点上。这项操作比较容易被疏忽,直到出现故障时才发现原来是 kube-dns 只运行了一份实例导致的故障。
总结
上面介绍了 Kubernetes Master 各个组件高可用可以采用的策略。其中 etcd 和 kube-apiserver 的高可用是整个方案的重点。由于存在多种高可用方案,集群管理员应当根据集群所处环境以及其他限制条件选择适合的方案。
这种没有绝对的通用方案,需要集群建设者根据不同的现状在多个方案中做选择的情况在 Kubernetes 集群建设过程中频频出现, 也是整个建设过程中最有挑战的一部分。容器网络方案的选型作为 Kubernetes 建设过程中需要面对的另外一个大问题也属于这种情况,今后有机会再来分享这个话题。
在实际建设过程中,在完成了上述四个组件的高可用之后,最好采取实际关机检验的方式来验证高可用方案的可靠性,并根据检验的结果不断调整和优化整个方案。
此外将高可用方案与系统自动化升级方案结合在一起考虑,实现高可用下的系统自动升级,将大大减轻集群的日常运维负担,值得投入精力去研究。
虽然本篇主要在讲 Kubernetes Master 高可用的方案,但需要指出的是高可用也并不是必须的,为了实现高可用所付出的代价并不低, 需要有相应的收益来平衡。对于大量的小规模集群来说,业务系统并没有实现高可用,贸然去做集群的高可用收益有限。这时采用单 Master 节点的方案,做好 etcd 的数据备份,不失为理性的选择。
来源:极术
原文:http://t.cn/Rs72Axn
题图:来自谷歌图片搜索
版权:本文版权归原作者所有